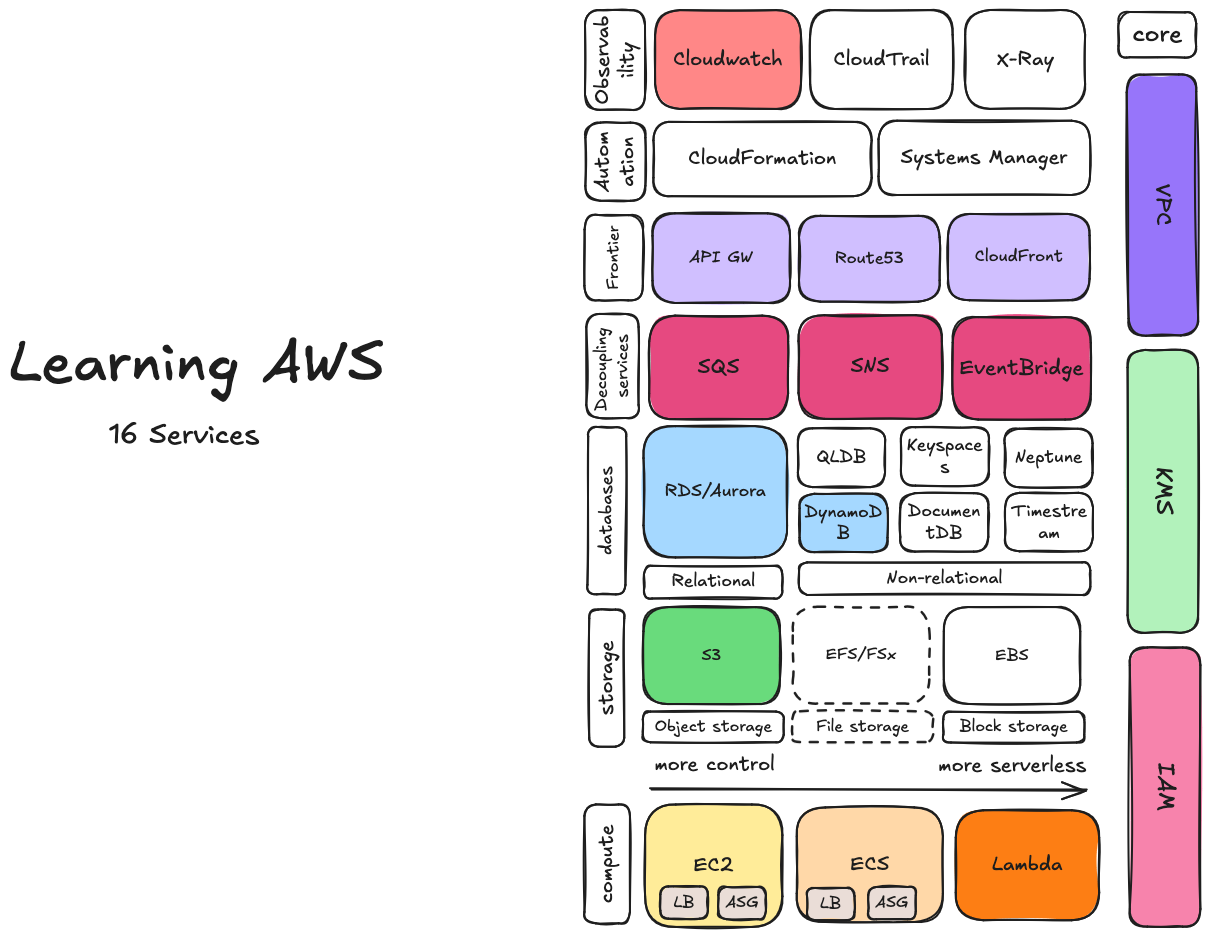
Introduction
In today’s world of web development, cloud knowledge has become a must-have skill. Whether you’re a frontend developer, backend engineer, or infrastructure specialist, understanding the cloud toolbox can significantly enhance your end-to-end vision. It allows you to design features with a broader perspective, weigh trade-offs, and make informed decisions that bring value to the business.
When I first started learning AWS, I felt overwhelmed by the number of services it offers. I struggled to understand how they all fit together, how to connect them, and how to choose the right service for a given solution.
This guide aims to give you an overview of AWS services. My goal is to help you build a mental map and provide a starting point for your AWS journey. If you already have experience in software development, by the end of this article, you’ll be able to draw parallels between concepts you already know and their AWS counterparts.
To keep things concise and focused, I’ll highlight foundational services and skip some of the more niche options. Once you understand these building blocks, exploring the rest of AWS will become much easier.
Basics
Businesses today solve diverse problems, from enabling customers to store photos to streaming videos or managing online marketplaces. To address these challenges, we design software systems composed of interconnected components—like LEGO bricks. The way you assemble these components determines how secure, efficient, and maintainable your system will be.
In the cloud, and particularly with AWS, software engineers typically interact through a web-based console, a command-line interface (CLI), or tools like Terraform for infrastructure as code. Let’s stick to the web-based console for simplicity. When you first log in, you’ll see something like this:
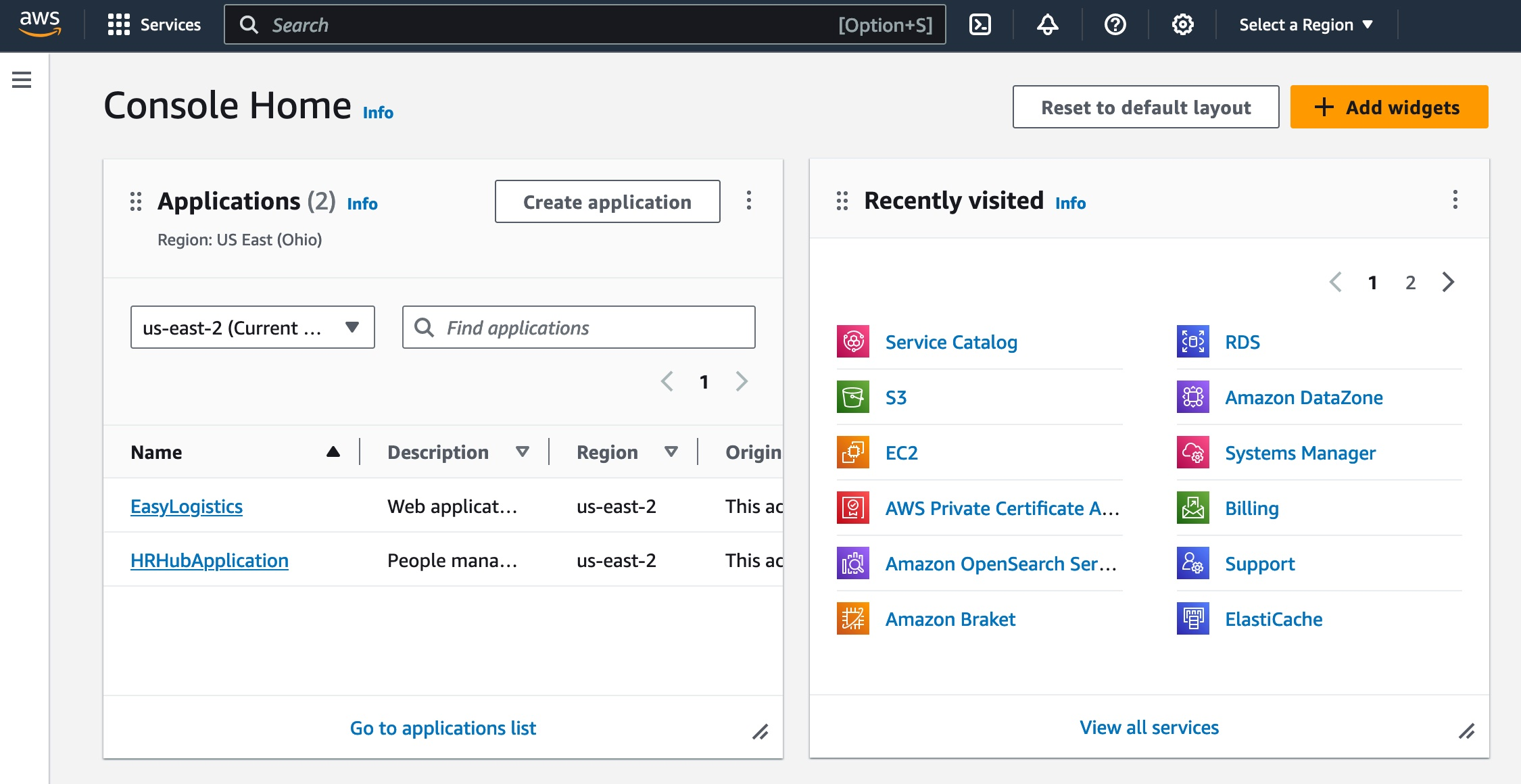
From this interface, you can create, configure, and manage AWS services.
Regions and Availability Zones
AWS introduces key concepts to ensure resilience: regions and availability zones (AZs). To understand these, let’s break down AWS infrastructure into basic hardware components:
- Servers: Physical machines that store and process data.
- Switches: Devices that connect servers within a data center.
- Routers: Tools that direct data between networks.
These components are housed in large facilities called data centers. A region is a geographical area with multiple data centers, and each region is divided into several availability zones. An AZ consists of one or more data centers connected by high-speed links, enabling rapid data synchronization.
This redundancy ensures reliability. For example, if one data center is destroyed—whether by a rocket or natural disaster - the others continue functioning. However, there are trade-offs when working across regions:
- Higher latency: Data transfer between distant regions is slower.
- Increased complexity: Managing inter-region setups is challenging.
- Additional cost: Transferring data across regions incurs fees.
Most AWS services are region-specific, meaning they operate within a single region, though workarounds like VPNs or global tables exist for cross-region needs.
Introduction to AWS Services
AWS services can be divided into several categories:
- Compute Services: Provide processing power to run applications, ranging from traditional virtual machines to managed container services and serverless computing.
- Storage Services: Include file storage, block storage for virtual machines, and object storage.
- Databases: Offer managed databases, both relational and NoSQL, to handle structured and unstructured data.
- Decoupling Services: Enable communication between different parts of an application in a loosely-coupled manner.
- Edge Services: Bring applications closer to end-users, reducing latency and improving user experience by caching and processing data at edge locations.
- Automation Services: Help automate infrastructure provisioning, deployment, and management, enabling consistent and repeatable processes.
- Observability: Provide tools to monitor, trace, and log application performance and infrastructure, aiding in issue detection and resolution.
- Core Services: Fundamental for securing access, managing permissions, and establishing network configurations.
Compute
Compute services provide resources to run and execute your code.
To better illustrate the types of compute resources AWS offers, consider the following analogy:
Using your own car: You have complete control over your car, allowing for customization, but you are responsible for maintenance, repairs, and fuel.
- Similar to Virtual Machines (VMs) in AWS: You configure your operating system, runtime environment, and software, but must manage updates, patches, and failures.
Using a car-sharing service: You select a pre-configured car that meets your requirements, with some flexibility to customize. Maintenance is partially managed for you.
- Similar to Containers: Offer isolated environments with efficient resource use, sharing the underlying infrastructure without full maintenance responsibility.
Using a taxi service: You simply book a ride, and everything else (driving, repairs, fuel) is managed for you.
- Similar to Serverless computing: Focus only on your code and logic while AWS manages infrastructure, scaling, and uptime.
EC2
So, EC2.
You have a computer right. It has some OS, and a hardware: e.g., CPU, that executes your code. It has a main memory, a network card, a hard drive or SSD. All of this you can buy and combine in many ways to get the PC configuration you want.
EC2 allows you to do very same except that hardware is not under or on your table, but somewhere hundreds or thousands kilometers away. Though usually you’re not the only user of that hardware, a few dosens of other OS from other AWS accounts are sharing this hardware, though note that there is an option to have a completely dedicated hardware and don’t share anything (see: Dedicated Hosts)
So what is actually happening is that some orchestrator (called Hypervisor) manages your Guest OS, makes sure all are given their quant of time to be executed and progress, and implements isolation, so that nobody from other AWS account can access your memory addresses.
Ec2 Instance Types
You can configure different type of EC2 instances (or in AWS language different machine families). This is KIND OF the bundle of specific processor (cores) and RAM or Storage or GPU that fit specific task:
- General Purpose (good for most apps)
- Compute Optimized (higher computer power for tasks requiring significant CPU performance)
- Memory Optimized (more ram for memory optimized tasks)
- Storage Optimized (optimized for sequential large data processing)
- Accelerated Computing (GPU. for ML/Graphics)
You can additionally plug in external detachable volumes. They call it Elastic Block Storage (EBS). They have options that vary by price, storage size, speed and purpose.
- General Purpose SSDs
- Provisioned IOPS SSD (for Databases with random access operations)
- Throughput Optimized HDD (sequential big data processing)
- Magnetic Storage (old and slow, but cheap)
Let’s now talk about pricing.
Standardly when you create a EC2 VM you choose on-demand types with pay-as-you-go model, so every hour or second you pay a few $.
There are also reserved instances. You can commit to use for 1 or 3 years only specific instance type, in specific region, with specific OS and pay significantly less in return.
And last, there are somewhat similar “savings plans”. You also commit to pay for 1 or 3 years, but for example you say I will pay 1$ per hour. but have less restrictions on instance type, for example you can change it as much as you want as well as some other params. But you pay a bit more than with reserved instances.
So, usually there is a general rule: the less flexibility you have in terms of changing instance type, and the longer you pay in advance the more you save, and vice versa.
There are many more other configuration options, as I mentioned in the beggining, using EC2 you have lots of control which means you have to handle many things like networking, scalability, security by yourself, therefore you have lots of options on EC2 page to do that. I would like to talk about such non-functional requirements such as scalability and fault-tolerance. Assume your business has commitment (SLA) to deliver 99,99999% of the uptime. Simplifying, you can face two types of problems:
User traffic can grow, maybe even change several times during the day (say more people use taxi service during the day and less during night time.) In order to handle large number of user requests you’d want more resources in your system, like CPU and Memory. Say we use EC2 instances. You can go two ways, make EC2 instance larger (with more CPU, RAM and whatever you need) this is called vertical scaling. So, simply speaking you’d have some script that would measure the change in user traffic. Then you’d stop accepting user requests, terminate the EC2 instance, would recreate a larger one and resume accepting user requests. But this doesn’t look quite good, since we have SLA of high uptime (availability). Even though if you’d somehow manage to grow your resources within a single machine this is complex and not efficient given the requirements. Another way you can go is to have a simple program that is actively waiting for incoming requests and on the background has a list of services that you can create on demand (for example when trafic grow or shrink and register them in your redirect service) where it can redirect such requests to further process the request. This is called horizontal scaling. Such service is called load balancer.
In AWS you can setup Elastic Load Balancer. Essentially you can register a listener on specific port, with the rules, then you register a target (could be EC2 instances, Containers or Serverless functions) and it will check if your target is healthy (meaning is able to respond to healthcheck requests) and if it is, on request it will forward it to one of the targets.
In addition to rules you can setup weight to each target, meaning 70% to go to EC2 instance A and 30% to go to EC2 instance B.
There are several types of load balancers that operate on a different level of the network stack
- Application Load Balancer (L7)
- Network Load Balancer (L4)
- These were main two, that you usually would use, and there are other two, like GWLB and CLB, but don’t focus on them now
And thats all you need to know about LBs
There is another important somewhat related concept of Autoscaling Groups.
Essentially what you can do is to create a template with preconfigured setup of your EC2 instance, where you say I have 2GB RAM 3 cores of M isntance family, Linux, and so on. Then you save this template and you can use this template in special scripts to recreate groups of such instances without configuring them manually one-by-one. Why would you need this? There are many options to setup scaling policies, registering alarms and reacting on alarms how you should scale, for example when expected number of running instances in a group is 10, but now it is too low, or incoming traffic became too high.
Also you can define lifecycle hooks to apply some custom actions when instances start or terminate which makes all thing even more customizable.
EFS
- there are options to connect an elastic file system to your instance that can be shared by multiple instances
VPC
- Last thing to mention is networking. Usually you want your instances to be addressable, so that they can communicate as internally between each other, with a database, externally with the client. That is why before you create an instance, usually you or your operations team create a virtual network, some subnets in there and network interface of each instance would belong to one of these subnets. So that they can communicate. You have separate subnets and some rules for incoming and outgoing traffic to VPC, like Network ACLs and Security Groups.
ECS (Amazon Elastic Container Service)
When moving one step above virtual machines, we get into the world of containers. Think of containers as lightweight OS processes that encapsulate your application and its dependencies while isolating the process, securing it, and restricting its view of the file system and underlying resources.
Docker is the most common tool for managing containers. With Docker, you define a file called a Dockerfile, which lists the necessary dependencies and instructions to compile and run your application. The Docker engine then interprets this file, builds an image, and creates an executable environment. You can then docker run this image to spawn as many instances of your containerized app as needed.
However, in production setup it is usually insufficient to run a single container. Usually you have multiple services that communicate with each other. Moreover, some services should be isolated from other groups. Also usually you need at least 1 replica of the container for redundancy if service crashes. Similarly, you would like to adapt to the incoming load by increasing the number of containers or decreasing them. You would also like to distribute load evenly accross your services, so that one service is not over or under utilized. As you can see all very much like with VMs, except that containers can usually start much faster like a program on your computer is started much faster, than booting OS and then starting the program.
This is where container orchestrators come in. In standalone setups, you’d use Docker Compose or similar tools for local orchestration. Nowadays the most popular container orchestration tool is Kubernetes, but in this article we talk about AWS, so on AWS, what you use is either Amazon EKS or Amazon ECS (Elastic Container Service). I would like to talk about the latter, because it is much faster and easier to get it running, than creating your own, even though managed kubernetes cluster.
So, ECS is a fully managed container orchestration service that helps run, stop, and manage containers. Let’s discuss the most important components of it:
So, thing to understand is that ECS uses EC2 instances under the hood. They’re running all the time, and what you do, you define so-called task definition, its your blueprint (we just discussed similar template-blueprint that spawn EC2, but this thing is for spawning preconfigured set of containers (just as a side know for those who knows Kubernetes this is somewhat similar to a Deployment)). Basically in the task definition you say: I want minimum 3 replicas, I want 3 vCPUs and 1GB RAM per container, I can setup where to store logs, some extra storage to attach. And one of the most important things there is launch type. Launch type is the place where you say either I want to manage scalability (meaning creating or destroying containers myself, and do all the related maintenance of EC2) or I want to lose access to EC2 instances, but please scale containers up and down based on some metric. For example when CPU utilization becomes higher than 50% create more containers.
That’s all you need to know about ECS.
AWS Lambda
Let’s move up one abstraction layer. Here we are. At serverless mountain peak.
All you left with is the code. You don’t need to be concerned with scalability and maintenance. Well, maybe just a bit. What AWS offers here is Lambda functions, probably second most popular service after S3.
If a virtual machine is like owning and maintaining a car, and containers are like using a car-sharing service, then Lambda is like ordering a taxi. You specify where you want to go (the code you want to run), and AWS takes care of everything else—from picking the car to driving it.
Just to get you the right feeling of what is it capable of:
- you can have a Web API and lambda can go to the database, take some entity, process it and return back the response
- lambda is highly integrated with many of AWS services, you can have some other service that in response to some event, for example when resource usage is high will invoke the lambda, or you have updated entry in the database that can also call the lambda. Or another lambda can call the lambda in a chain. Such asyncrounous, event driven capabilities and high integration with other services allow you to have high composability
There are some imporant limitations you need to be aware:
- Execution Time: Lambda has a maximum execution time limit, currently capped at 15 minutes per invocation.
- Memory and Storage: Limited by memory configurations (128 MB to 10 GB) and temporary disk space (512 MB).
- Response payload is 6MB
- Cold Starts: Functions that haven’t been invoked recently might experience a slight delay when first run due to initialization time.
- Stateless Nature: Lambda functions are stateless, meaning they can’t retain data between invocations. You’d need to use external services like S3 or DynamoDB for persistent storage.
Benefits: With Lambda, you only pay for the compute time you use. When your function isn’t running, you’re not paying for any infrastructure, making it cost-effective for many use cases.
Storage
Now, let’s talk about storage. There are 3 types of storage that are usually outlined in the literature. There are block, object and file storage types. Let’s dive in how they’re implemented in AWS and what they are.
Block Storage. EBS provides block-level storage volumes for use with EC2 instances. The unit of operation is a block of bytes, meaning data is stored in raw blocks without any inherent structure. To use this type of storage effectively, you typically need to format it with a file system (e.g., ext4 or NTFS) so that you can perform higher-level operations such as reading, writing, searching, and deleting files. EBS is perfect for databases, file systems, and any workload requiring persistent block-level storage. It offers various volume types, optimized for performance or cost, and allows snapshots for backup and recovery.
File storage. EFS provides scalable, fully managed, elastic file storage that can be mounted to multiple EC2 instances and accessed like a typical file system. The unit of operation is a file, and you interact with it using a standard file system interface. EFS is well-suited for shared access scenarios, such as content management, web serving, or home directories.
Object storage is another way to access data. Such storage type works with objects. Not with memory addresses like in block storage, not with files, but with Objects. Objects are blobs of data stored somewhere in the cloud, which is abstracted away from the user. User has to know a unique identifier, a key, to retrieve an object. Also object has some metadata, that describes an object.
Andd the object storage is represented by Amazon Simple Storage Service (of S3) in AWS world. This is the most heard and one of the most (if not the most) popular AWS service. This is one of the must-known services that you will most likely use in every job when you work with AWS Cloud.
S3 is designed for storing large amounts of unstructured data of different types such as backups, media files, and data archives, configuration system, static content distribution with CDN. S3 is one of the oldest AWS services and has lot’s of features that we will briefly cover.
So, what do we have?
Basic information
- Object storage. Store objects in buckets, which is a container for your objects
- Objects are immutable, so that if you want to update it, AWS removes and recreates a new one under the hood.
Versioning
- You can enable versioning. So, when you update a file with the same key, it gets a new version. You can retrieve different versions of a file by explicitly specifying a version name
- Versioning also a way to protect a file from accidental deletion.
- S3 Provides 11 9’s of durability meaning, generally you don’t have to care about replication if durability is a concern. Of course if you need lower latency or must comply with local data regulation standartds that is another question.
Storage classes
- You can choose to store your objects in different storage classes. Meaning that if you access your data infrequently you may want to pay less, in return they take from you the ability to access objects with low latency and even pay more for such object retrievals.
- There are
- S3 Standard tier is called standard because its a default
- S3 Intelligent Tiering
- S3 Standard-Infrequent Access
- S3 Glacier
- S3 Glacier Deep Archive
- I won’t provide detailed guide in this article, but just explain the intuitive difference between the teirs. Let’s take the following example. Let’s say we have S3 bucket called
photos, say we have two folders,current_yearandprevious_yearandarchive. Objects in the current folder are accessed every day. Previous year once in a month and archive once in half-year. What we could do is to keep objects we access and update very often in Standard tier. This way we pay maximum for the storage, least amount for retrieval cost. Also we can access such photos instantly. For previous year folder we can put all objects in Infrequent Access tier. We would pay less for storage and a bit more for retrieval compared to Standard tier. Access is also instant as in Standard tier. Lastly, for archived objects we can think about Glacier tier. You pay the least if you decide to store the objects there, but the retrieval cost and retrieval time is highest. - Such rules like “please store all objects under such path in Glacier or IA tier” are implemented via Lifecycle Policies. you can define rules to transition your objects between storage classess or deleting them after some defined period of time.
- But maybe you don’t want to care about moving objects each year between folders to move them to a proper tier. Then you might want to use S3 Intelligent Tiering which automatically moves objects between tiers depending on how frequently they are accessed. Meaning that it could move it a tier higher or lower. It has slightly higher cost to store metadata about access time of each object, but in return you are free from manual management of object tiering.
- Speaking about security S3 has options to encrypt your objects either on the client side or at the server side. Also there are different options with regards WHO manages the key. AWS or you. If AWS - there are lot’s of advantages like automatic rotation and …
Lambda events
- You have various events happening in your bucket, like delete, get, upload, etc. You can define some actions to react on these events. For example to start some extra post processing after the object was uploaded or raise an alarm.
Object Locks
- You can protect your objects from deletion for some sensitive data protection or accidental or malicious deletion. There is a special option (Compliance mode) when no one even a root user is unable to delete object until retention period expires.
- Objects are read-only, so that if you want to update it, you remove and recreate one.
Multipart Upload.
- If you need to upload a large object several gigabytes in size (up to 5 TB is the limit) you have an option of multipart upload: AWS SDK will split file into several chunks, parallel upload to speedup the process.
Databases
Databases are an abstraction on top of the block storage. There are different non-functional properties and ways how to structure your data with different types of the databases. I will not focus on their differences in the context of the article, but rather emphasize what AWS has to offer.
One of the most common and the oldest type is Relational Database type. AWS offers Relational Database Service or RDS. RDS is a fully managed relational database service. So you can create a relational database, where you can configure an EC2 instance where this database will be hosted, you can choose an engine, like
- PostgreSQL
- MySQL
- Oracle
- and of course Aurora that provide additional management
- etc…
RDS handles routine database management tasks such as backups, patching, and scaling, allowing you to focus more on your applications rather than database administration.
RDS supports horizontal scaling through Read Replicas, allowing you to distribute read traffic and enhance performance. For high availability and fault tolerance, RDS provides Multi-AZ (Availability Zone) Deployments, ensuring your database remains operational even if there’s an infrastructure failure.
For most use cases—whether you’re building an e-commerce app, content management system, or similar applications—RDS is an excellent choice.
Speaking of NoSQL databases there is a large variety of them:
- Key-value like
- Document databases like DocumentDB
- Graph databases like AWS Neptune
- Time Series databases like Amazon Timestream
- and Key-Value like DynamoDB
As we cover the most essential services I would like to focus on the DynamoDB for the remainder of this chapter.
So, as usual, this is a fully managed key-value NoSQL database service that focuses on performance and scalability in the first place. It is designed for any use-case that needs high-throughput, low-latency access to large amounts of unstructured data.
When working with Dynamo you need to learn some nuances:
- First is the data model and ways to interact with it. There are some nuances when doing data modeling for KV storage, and specifically for Dynamo. This includes understanding about Primary Key, Sort Key. Local and Global secondary indexes. Which types of querying is possible with DynamoDb and which are not. What is vertical partitioning. How to implement pagination. I encourage you to get familiar with this once you feel the need to do so.
- Second is configuration options of Dynamo. And there are a few things you need to know. DynamoDB automatically scales to handle large amounts of traffic. It supports on-demand scaling or provisioned throughput, where you set read/write capacity units, and DynamoDB adjusts to meet your needs. DynamoDB is fully serverless, meaning you don’t need to manage infrastructure, and you can integrate it with AWS Lambda to build event-driven applications.
- High Availability and Durability: DynamoDB is spread across multiple AWS Availability Zones, ensuring that your data is always available and durable.
Decoupling services
Mostly for event-driven architecture to signal the state of some step of the process, for the cases when consumers are limited in scale and cannot handle same load that is produced by producer
SQS
Amazon SQS is a fully managed message queuing service that enables decoupling of components within a distributed system. It helps in scenarios where producers can produce messages at a faster rate than consumers can process them.
Key Concepts:
- Delivery Semantics:
- At-Least-Once Delivery: Messages are delivered at least once, but occasionally more than once.
- At-Most-Once Delivery: By setting appropriate configurations, it is possible to achieve at-most-once delivery, though this is not the default behavior.
- Exactly-Once Processing: Not inherently guaranteed by SQS alone but can be implemented with idempotent consumers or additional logic.
- Queue Types:
- Standard Queue: Offers nearly-unlimited throughput, at-least-once delivery, and best-effort ordering.
- FIFO Queue: Guarantees that messages are processed exactly once, in the exact order they are sent.
- FIFO (First-In-First-Out):
- Ensures that the order of operations is preserved and that each message is processed exactly once.
- Useful for scenarios where the order of operations is critical, such as financial transactions or logging.
SNS
Amazon SNS is a fully managed pub/sub messaging service that allows you to decouple and scale microservices, distributed systems, and serverless applications. SNS is designed for high-throughput, push-based, many-to-many messaging.
Key Concepts:
- Pub/Sub Model:
- Publishers: Send messages to an SNS topic.
- Subscribers: Receive messages from an SNS topic. Subscribers can be SQS queues, Lambda functions, HTTP/S endpoints, or email addresses.
- Message Delivery:
- Fan-Out: One message published to a topic can be delivered to multiple subscribers.
- Push Mechanism: SNS pushes messages to subscribers rather than them pulling messages.
- Use Cases:
- Real-time broadcasting of messages to multiple services.
- Sending notifications to users via multiple channels (email, SMS, mobile push notifications).
EventBridge
Amazon EventBridge is a serverless event bus service that makes it easy to connect applications using data from your own applications, integrated software-as-a-service (SaaS) applications, and AWS services.
Key Concepts:
- Event Bus:
- A logical pipeline to receive, filter, and route events to target services.
- Can connect multiple event sources to multiple event targets.
- Event Sources:
- AWS services, integrated SaaS applications, custom applications, and more.
- Custom event buses for separating different types of events.
- Event Targets:
- AWS Lambda functions, SQS queues, SNS topics, Kinesis streams, Step Functions, and more.
- Enables the orchestration of complex event-driven workflows.
- Rules:
- Define how events are routed to one or more target functions or services.
- Supports event filtering to ensure that only relevant events are processed by a given target.
- Schema Registry:
- Allows you to create, store, and manage event schemas, making it easier to understand the structure of events.
Edge services
- CloudFront: AWS’s Content Delivery Network (CDN) service that distributes content globally with low latency.
- Lamda integrations
- AWS integrations
- Route 53: AWS’s scalable Domain Name System (DNS) web service that routes end-user requests to the appropriate resources. Can you it as a standalone DNS web service, but also it allows integration with various AWS services. For exampe API Gateway.
- API Gateway: AWS’s fully managed service that allows developers to create, publish, maintain, monitor, and secure APIs at any scale.
- Integration with WAF
Automation services
I would like to focus particularly on infrastructure automation as the very important aspect of modern cloud development.
CloudFormation allows you to define your AWS infrastructure in code using JSON or YAML. This approach makes deployments consistent and repeatable, which is vital for complex environments.
Consider a scenario where you need EC2 instances with load balancers and databases. With CloudFormation, you can define these resources once in a template and use it to spin up entire environments with a single command.
I would advice you not to look into CLoudFormation, but rather get familiar with more popular alternative like Terraform that has simpler syntax, better state management, and multi-cloud compatibility.
Observability
Amazon CloudWatch
- Must-Have: CloudWatch is an essential service for monitoring and observing your AWS environment. It’s not just a single service, but an umbrella of features that provide monitoring and management capabilities for AWS and your applications.
- Metrics: CloudWatch collects and tracks metrics from your AWS resources (like CPU utilization of EC2 instances) and custom metrics that you define. You can visualize this data using dashboards to get real-time insights.
- Logs: CloudWatch Logs centralizes the logs from your applications, AWS services, and systems, allowing you to monitor, search, and analyze log data.
- Alarms: With CloudWatch Alarms, you can set thresholds on your metrics and trigger notifications or actions (like auto-scaling or Lambda invocations) when those thresholds are breached.
- Events: CloudWatch Events helps you respond to changes in your AWS environment in near real-time. You can configure rules to trigger actions automatically when certain events occur (e.g., starting a Lambda function when an EC2 instance changes state).
CloudWatch is critical for maintaining the health of your AWS environment, offering visibility into performance, detecting anomalies, and automating responses to operational issues.
AWS CloudTrail
- Just Play With It Once: AWS CloudTrail is a service that logs and tracks all API calls and activities across your AWS environment. Every time someone makes a request to an AWS service, CloudTrail records the details (who made the call, when, and from where).
- Audit and Compliance: CloudTrail is invaluable for security, auditing, and compliance. It helps you track changes in your environment, identify suspicious activity, and maintain accountability.
For beginners, it’s essential to explore CloudTrail to understand how you can monitor and review activity across your AWS account, ensuring visibility into who is doing what.
AWS X-Ray
- Just Play With It Once: AWS X-Ray is a service that helps you analyze and debug your distributed applications, particularly microservices. It provides tracing for requests that pass through your system, helping you identify performance bottlenecks, latency issues, or failures in specific parts of your application.
- Visual Service Map: X-Ray provides a visual map of your services and their interactions, making it easier to understand how your application components work together and to diagnose issues.
For beginners, X-Ray is worth exploring to see how you can gain deep insights into the behavior of your microservices or distributed applications, but it’s not something you’ll need to use constantly unless you’re dealing with complex, multi-service architectures.
Core Services
I can outline several core services that is integrated with every other AWS service.
IAM
- Access Management. Manage access to your resources. Says who has permission to use what resource (a service in AWS). So, everything spins around identites and resources. This relation is described in a policy.
- Say Mr. X can read S3 objects
- Identities.
- Users
- User is a type of identity that you create for a single person or application. User Groups
- At start = root, you start by entering your username and password
- In real software development = multiple accounts “dev, prod, billing”
- To dive deeper into this topic - see Governance services like AWS Organizations, Control Tower, Billing, …
- Roles
- Roles is a temporal entity that can be dynamically attached, detached to a User or application
- This process is called Assume Role action. And when service or user assumes role it loses its old permissions and acquires new ones described in a role
- and its possible to assign a certain life time when assumption of the role is expired, when you would have to re-AssumeRole once again.
- Generally roles are more advisable to use instead of Users
- Users
- Policies
- Identity-based policies
- Role-based policies
KMS
- I’ve added it to the core services, because it is required and integrated with most of other AWS services, especially when you are doing production software development
- Key Management Service is essentially a service that helps you to encrypt your data at rest.
- Just as a side note: to encrypt data in transit AWS does it on multiple levels, physical in DCs, network layer within and between VPCs, and TLS at the application layer. So its not responsibility of KMS
- It handles the lifecycle and access to the cryptographic keys. There are few types of KMS keys in aws:
- AWS Managed
- AWS Owned (AWS uses it across multiple accounts to encrypt data in specific service where AWS Owned key option is supported)
- Customer Managed Keys.
- There are symmetric and asymmetric key support
- Envelope based encryption
VPC
- A service that allows to create a networks based on IP range. Services that leverage this VPC (mainly EC2) are isolated from other services on network level. You can create entry and exit points via NAT Gateways and Firewalls.
- There are many was how you can share resources between two isolated VPS, via AWS RAM or Gateways, but this should not be your focus at the beggining
General recommendations:
- I would try to build my own VPC and run some EC2 instance with a web service just to get a feeling how it might work
- I would click around IAM and KMS to get familiar with the interface, maybe tested how can I assume role on behalf of another user. But I would play with policies step by step when I learn some of the compute services like Lambda, which I cover in the next section. This will make learning persistent and more intuitive.
Where to practice?
- For the reference use available exam guides or courses. E.g., Cloud Practitioner or AWS solution architect associate
- How to get hands-on experience
- This can be painful, so give yourself time. Don’t rush it
- AWS Free Tier
- CloudGuru. Wait for discounts
- I don’t recommend following tutorials. At least blindly
- Remember your goal, at least now, is not to become an expert of AWS, but get some basics of some services and understand how they could be wired together
- And remember, if you aim for everythin, you hit nothing. Focus on one-two services at once.
Conclusion
If you ask me, “Sergei, name the top 5 AWS services I must know,” my answer would be: It depends. It depends on what you’re working on. Here’s how it breaks down:
For Data Engineering or working with real-time data:
- Kinesis
- Firehose
- S3
- IAM
- KMS
- EMR
- Flink
For event-driven, customer-facing applications:
- Lambda
- EventBridge
- DynamoDB
- S3
- API Gateway
For tasks more on the server-side spectrum:
- EC2
- API Gateway
- VPC
- IAM
If I try really hard to name top 5 services that are universally useful across nearly any job, these would be:
- IAM (Identity and Access Management)
- KMS (Key Management Service)
- Lambda
- S3
- CloudWatch Logs
Hope you’ve learned something! 👋